
Local automation
Welcome
Once again I have a goal, write every month at least one article. Sounds easy, but unfortunately for me, it is not. The idea behind this blog is to write content that will be helpful for me(and hopefully for my readers as well). For example, when I need basic Nginx configuration I used to open this post from 2021. Now I’m older a bit, so I decided to switch once again to Doom Emacs(?!!) and start writing my own code/config snippets. As it also can be useful, probably I will write about it someday.
Introduction
Ok, so what do I mean by local automation? I would say all actions, that allow
me to do things faster and make fewer errors while (mostly) typing. Also, it
could be useful during presentations, or live coding - as less typing is a
smaller chance of typo. That is why I will break this article into three
parts; HTTP requests and wrappers.
HTTP requests
For a very long time, the go-to tool was curl. Great, always available command line tool. Unfortunately, there is one small issue. It’s hard to keep requests and collect them in collections, it’s great for one-time shots or debugging, but for constant working with API could be painful.
To solve it, I started working with tools like Postman/Insomnia. Then eh… strange licensing model, or changes which occurred from Kong side click, definitely push me again for some lookup.
After checking different very popular tools and those not such well known I decided to use… Ansible. Sounds strange right?
Let me explain this decision. For example, look at this code.
---
- name: Testing dummyjson.com
hosts: localhost
gather_facts: false
tasks:
- name: Get random content
register: output
ansible.builtin.uri:
url: https://dummyjson.com/products/
return_content: true
- name: Filter content
ansible.builtin.set_fact:
stock: "{{ output['json']['products'] | selectattr('title', '==', 'iPhone 9') | map(attribute='stock') | first }}"
- name: Assert results from
ansible.builtin.assert:
that:
- "{{ stock }} is eq(94) "
As you can see within 19 lines of easy-to-read code, I’m able to query the data endpoint, select needed variables, and assert the result. But… let’s focus on Ansible filters.
"{{ output['json']['products'] | selectattr('title', '==', 'iPhone 9') | map(attribute='stock') | first }}"
In general, it’s jq replacement. First, we define a dictionary with our needed content. selectattr is an Ansible filter that allows us to select the object(list or dict) based on our query. Then we have map, which chooses the needed element from the dict, at the end we’re using first filter, which just gets the first element of the created dict.
Now you can ask me about authorization. Easy.
---
- name: Query endpoint with auth
hosts: localhost
gather_facts: false
tasks:
- name: Query endpoint
vars:
username_password: "admin:password"
ansible.builtin.uri:
url: https://example.com/
method: GET
headers:
Authorization: Basic {{ username_password | string | b64encode }}
validate_certs: false
register: query_results
Maybe it’s a bit more complex, than adding it to Postman, but:
- It’s easy to control as code
- git friendly
- fully open-source
- sometimes fast
- high level of flexibility with data manipulation, so we can chain our requests!
Wrappers
That is probably my favorite and most used category. I’m using two types of them. Linux aliases and Makefiles. Both have different use cases, as well as usability levels.
Aliases
In most cases, when we become Unix users, after a while our .bashrc/.zshrc become long, and complex. For example, my zsh configuration is 112 lines long. And it’s great, starting from:
# AWS CDK
export JSII_SILENCE_WARNING_UNTESTED_NODE_VERSION=true
Through AWS aliases:
# get IDs of all named instances
alias ec="aws ec2 describe-instances --output yaml --query 'Reservations[*].Instances[*].[InstanceId,Tags[?Key==\`Name\`].Value]' --no-cli-pager"
# connect with instance over ssm
alias ssm="aws ssm start-session --target"
Then at the end I have aliases for working with remote docker, over sockets:
dxdo() {
export DOCKER_CONTEXT=digital-ocean
export DOCKER_BUILDKIT="1"
export COMPOSE_DOCKER_CLI_BUILD="1"
unset DOCKER_CERT_PATH
unset DOCKER_TLS_VERIFY
}
dcc() {
docker context create ${1} --docker "host=tcp://${1}.host.link:2376,ca=/Users/kuba/.docker/c/ca.pem,cert=/Users/kuba/.docker/c/cert.pem,key=/Users/kuba/.docker/c/key.pem"
}
dodcc() {
docker context update digital-ocean --docker "host=ssh://kuba@$(tf output -raw public_ip):4444"
}
Right, so what’s wrong with aliases? Mostly all of them are global, and rather simple, without error handling. Also not very good for cooperating with friends, or showing up during public talks. Now, let’s move to Makefiles. I’m using them for most of my project/presentation-related activities. For example, that is Makefile from my The Hack Summit talk:
define deploy
$(eval $@_REGION = "eu-central-1")
$(eval $@_STACK_NAME = $(1))
cfn-lint $($@_STACK_NAME).yaml
aws cloudformation deploy --stack-name $($@_STACK_NAME) \
--template-file $($@_STACK_NAME).yaml \
--region $($@_REGION) \
--capabilities CAPABILITY_NAMED_IAM
aws cloudformation wait stack-create-complete --stack-name $($@_STACK_NAME)
aws cloudformation describe-stacks --stack-name $($@_STACK_NAME) --query "Stacks[].Outputs" --no-cli-pager
endef
define destroy
$(eval $@_REGION = "eu-central-1")
$(eval $@_STACK_NAME = $(1))
aws cloudformation delete-stack --stack-name $($@_STACK_NAME) --region $($@_REGION)
endef
clean-1:
@$(call destroy,"example-1")
clean-2:
@$(call destroy,"example-2")
clean-3:
@$(call destroy,"example-3")
clean-4:
@$(call destroy,"example-4")
example-1:
@$(call deploy,"example-1")
example-2:
@$(call deploy,"example-2")
example-3:
@$(call deploy,"example-3")
example-4:
@$(call deploy,"example-4")
generate-ssh-config:
aws cloudformation describe-stacks --stack-name example-2 --query "Stacks[].Outputs" --no-cli-pager | jq -r '.[][] | if .OutputKey == "THSInstance" then "Host \(.OutputKey)\n ProxyJump THSBastion\n PreferredAuthentications publickey\n IdentitiesOnly=yes\n IdentityFile /Users/kuba/.ssh/id_ed2219_ths\n User ec2-user\n Hostname \(.OutputValue)\n Port 22\n\n" else "Host \(.OutputKey)\n PreferredAuthentications publickey\n IdentitiesOnly=yes\n IdentityFile /Users/kuba/.ssh/id_ed2219_ths\n User ec2-user\n Hostname \(.OutputValue)\n Port 22\n\n" end' > ~/.ssh/config.d/ths
It’s one big wrapper around CloudFormation, with implemented stack watch, as well as ssh/config.d config generation.
Cool staff, and very easy to use, just after implementation. However, we can make it even smaller, for example this small file:
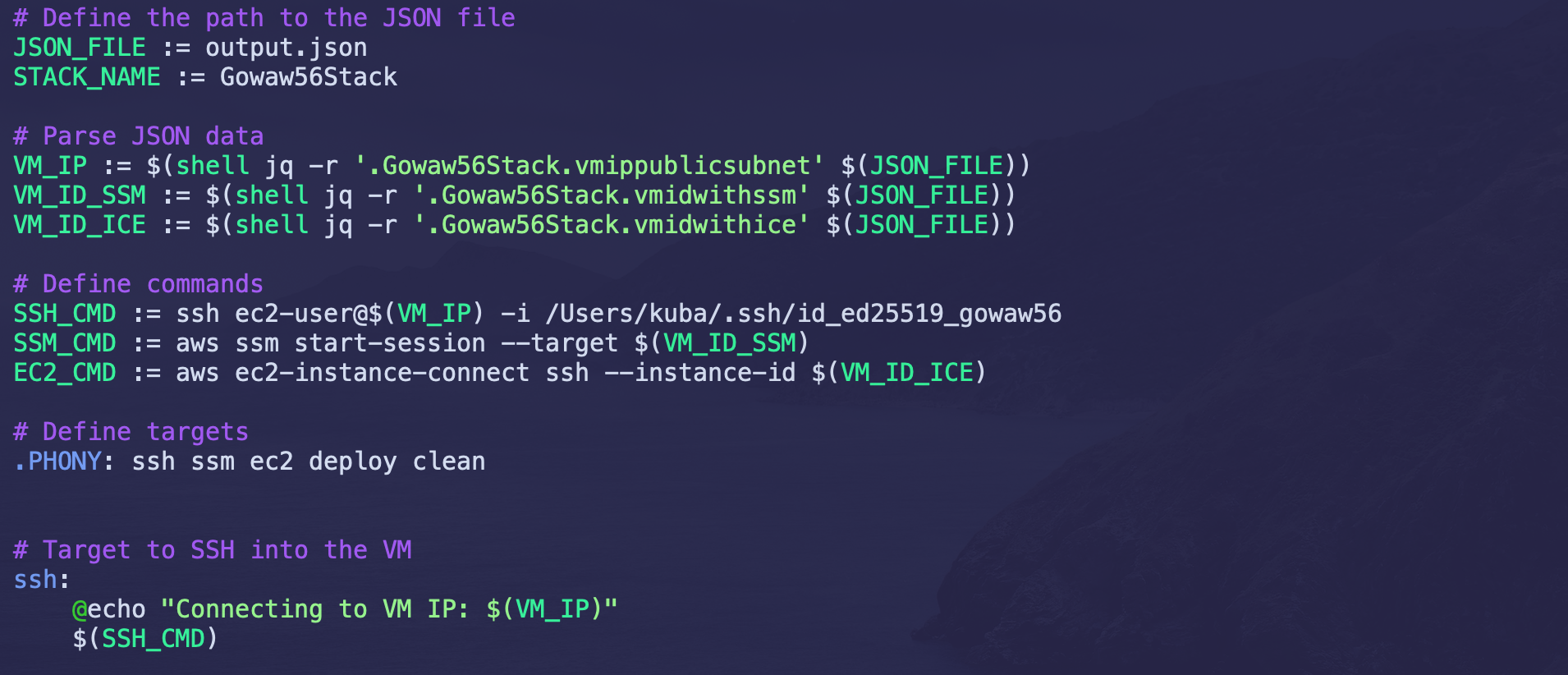
JSON_FILE := output.json
STACK_NAME := Gowaw56Stack
# Parse JSON data
VM_IP := $(shell jq -r '.Gowaw56Stack.vmippublicsubnet' $(JSON_FILE))
VM_ID_SSM := $(shell jq -r '.Gowaw56Stack.vmidwithssm' $(JSON_FILE))
VM_ID_ICE := $(shell jq -r '.Gowaw56Stack.vmidwithice' $(JSON_FILE))
# Define commands
SSH_CMD := ssh ec2-user@$(VM_IP) -i /Users/kuba/.ssh/id_ed25519_gowaw56
SSM_CMD := aws ssm start-session --target $(VM_ID_SSM)
EC2_CMD := aws ec2-instance-connect ssh --instance-id $(VM_ID_ICE)
# Define targets
.PHONY: ssh ssm ec2 deploy clean
# Target to SSH into the VM
ssh:
@echo "Connecting to VM IP: $(VM_IP)"
$(SSH_CMD)
# Target to start SSM session
ssm:
@echo "Starting SSM session for instance ID: $(VM_ID_SSM)"
$(SSM_CMD)
# Target to SSH into EC2 instance using EC2 Instance Connect
ec2:
@echo "Connecting to EC2 instance ID: $(VM_ID_ICE)"
$(EC2_CMD)
deploy:
@echo "Deploy stack: $(STACK_NAME)"
cdk deploy $(STACK_NAME) --require-approval never -O $(JSON_FILE)
clean:
@echo "Cleaning stack: $(STACK_NAME)"
cdk destroy $(STACK_NAME) --force
This time I decided that it was much more efficient to use Makefile during the public talk than typing everything manually, and exposing myself to unexpected history presentations.
Summary
As you can see, It’s quite easy to automate our DevOps workflow. Almost everything we can just share with others, and make them work more time efficiently, also what is very important. Everyone will be on the same page, with the same results(let’s say ;) ). As Makefiles and aliases are easy to understand, I believe that using Ansible as an HTTP request tool isn’t the first idea. I had the same, it was a matter of filter understanding. After I realize how to use them correctly, versioning HTTP requests and result manipulation become very smooth.