

Optimizing Video Localization with ML and AWS Batch
Welcome
As you may know, I had the opportunity to speak publicly during AWS Community Day Warsaw. The talk was about a non-trivial challenge related to AWS services. Since there was no recording available and the slides alone are not sufficient, I decided to write a blog post to document this homegrown project. During the showcase, you will see various services and encounter different issues. If you have any questions, feel free to reach out to me on LinkedIn or via email.
Tools Used in This Episode
- AWS CDK (Typescript)
- Python (MoviePy)
- AWS Translate | Transcribe | Polly | Batch | CodeBuild | CodeCommit | Lambda | etc.
What Is Video Localization?
Video localisation refers to the process of adapting a video’s content to make it suitable and appealing to a specific target audience in a different geographical region or cultural context. It involves modifying various elements of the video to ensure that it resonates with the local audience, considering language, culture, and preferences.
Video localisation aims to eliminate language barriers and make videos more relatable and engaging for audiences across different regions. It helps businesses and content creators expand their reach, improve user experience, and maximize the impact of their videos in global markets.
What Was My Use Case?
 |
|---|
In short, let’s imagine you have excellent learning materials in English, Polish, or Spanish. Unfortunately, you have a tight deadline, and your team lacks the skills for localising the content to German or Italian. You need to accomplish this task quickly. Alternatively, suppose you enjoy watching Polish sitcoms but don’t understand Polish, and there are no available subtitles. That’s the use case!
Project architecture
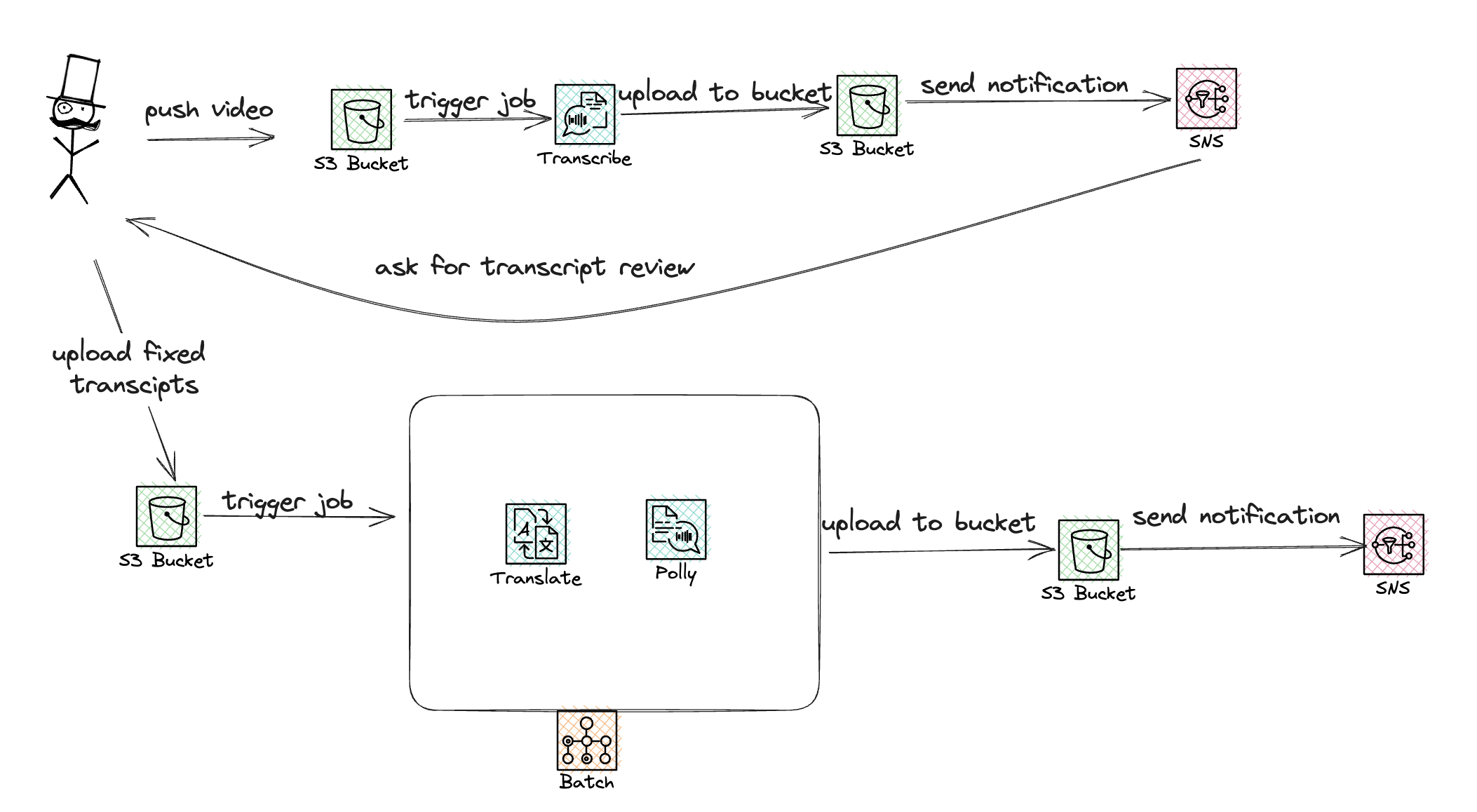 |
|---|
As you can see, the flow is relatively simple. We start as a human with a hat, and then:
- We push the base video to bucket one, triggering a Lambda function via S3 event.
- After the Transcribe job is complete, the file is uploaded to bucket two.
- This triggers SNS notifications.
- After review, the operator uploads the file to bucket three.
- This action triggers the batch job, which uses MoviePy code to combine subtitles and voice into a new video.
- The resulting video(s) are pushed to bucket four, and the operator is notified.
Decision records
This flow involves two non-obvious decisions, which I have documented in ADR records.
 |
|---|
 |
|---|
Implementation
The implementation was extensive, and I might need to split it into two or three different articles. However, I will cover all the important aspects, providing descriptions and comments.
Imports
If you are familiar with CloudFormation or Terraform, you probably don’t care about importing modules. However, in CDK, you can import services on a per-service basis, as shown in the following example:
import { readFileSync } from 'fs';
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as s3 from 'aws-cdk-lib/aws-s3';
import * as iam from 'aws-cdk-lib/aws-iam';
import * as batch from '@aws-cdk/aws-batch-alpha';
import * as lambda from 'aws-cdk-lib/aws-lambda';
import * as ecr from 'aws-cdk-lib/aws-ecr';
import * as ecs from 'aws-cdk-lib/aws-ecs';
import * as ec2 from 'aws-cdk-lib/aws-ec2';
import * as codebuild from 'aws-cdk-lib/aws-codebuild';
import * as codecommit from 'aws-cdk-lib/aws-codecommit';
import { S3EventSource } from 'aws-cdk-lib/aws-lambda-event-sources';
import * as sns from 'aws-cdk-lib/aws-sns';
import * as triggers from 'aws-cdk-lib/triggers';
import * as snsSubscriptions from 'aws-cdk-lib/aws-sns-subscriptions';
import * as s3Notifications from "aws-cdk-lib/aws-s3-notifications";
import path = require('path');
Default properties block
This is my favorite CDK feature. We can pre-define a set of properties and reuse them every time we need them. For example here is S3 bucket creation:
const defaultBucketProps = {
versioned: false,
encryption: s3.BucketEncryption.S3_MANAGED,
enforceSSL: true,
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
};
const rowVideoS3bucket = new s3.Bucket(this, 'RowVideoS3bucket', {
bucketName: cdk.Stack.of(this).account + "-initial-videos", ...defaultBucketProps
});
Inline Lambdas
In this case, we’re able to read the function’s code from the project structure, and then feed it with environmental variables. Which is very handy!
const TranscribeTriggerFunctionCode = readFileSync('./assets/TranscribeTriggerFunction.js', 'utf-8');
const transcribeTriggerFunction = new lambda.Function(this, "TranscribeTriggerFunction", {
runtime: lambda.Runtime.NODEJS_16_X,
handler: "index.lambdaHandler",
role: transcribeTriggerRole,
code: lambda.Code.fromInline(TranscribeTriggerFunctionCode),
environment: {
"TRANSCRIBED_VIDEOS3_BUCKET_NAME": transcribedVideoS3bucket.bucketName,
}
});
S3 Event Trigger
How to trigger the lambda function directly after uploading to S3, without EvenBridge? Just use this snippet.
transcribeTriggerFunction.addEventSource(new S3EventSource(rowVideoS3bucket, {
events: [s3.EventType.OBJECT_CREATED],
filters: [{ suffix: '.mp4' }], // optional
}));
CodeCommit
Ok, now we would like to build a docker container for our Batch, so we need to store code somewhere and upload code there during project deployment. CDK has a solution, which is very elegant. However, remember it’s initial commit only.
const repository = new codecommit.Repository(this, 'Repository', {
repositoryName: 'BatchServiceRepository',
code: codecommit.Code.fromDirectory(path.join(__dirname, '../assets/batch/'), 'main'),
});
CodeBuild
As we already have the code, we would like to build it. Here comes CodeBuild. Please note the part about environment. Flag privileged is needed If, we would like to build dockers.
const codebuildProject = new codebuild.Project(this, 'Project', {
projectName: 'RegistryWithBatchImagesProject',
source: codebuild.Source.codeCommit({ repository }),
role: codeBuildRole,
environment: {
privileged: true,
},
buildSpec: codebuild.BuildSpec.fromObject({
version: '0.2',
phases: {
pre_build: {
commands: [...],
},
build: {
commands: [...]
},
post_build: {
commands: [...]
}
},
}),
});
CodeBuild Trigger
That one is tricky. There is no easy way to trigger CodeBuild with CDK, you can use Step Function or another Lambda executed during CDK’s runtime. I decided to use Lambda, to avoid unnecessary complexity.
const RunOnceTrigger = new triggers.TriggerFunction(this, 'CodeBuildOnlyOnceTrigger', {
runtime: lambda.Runtime.NODEJS_16_X,
handler: 'index.lambdaHandler',
code: lambda.Code.fromInline(RunOnceFunctionCode),
role: lambdaRunOnceRole,
environment: {
CODE_BUILD_PROJECT_NAME: codebuildProject.projectName,
},
executeAfter: [
codebuildProject
]
});
Batch definition
That is the last worth noticing parameter. If you would like to use Fargate as compute model, you need to set the flag assignPublicIp to true. Without that, you cannot access the registry.
const jobDefinition = new batch.EcsJobDefinition(this, 'JobDefn', {
jobDefinitionName: 'JobDefn',
container: new batch.EcsFargateContainerDefinition(this, 'containerDefn', {
image: ecs.ContainerImage.fromRegistry(registry.repositoryUri + ":latest"),
cpu: 4.0,
memory: cdk.Size.mebibytes(8192),
assignPublicIp: true,
environment: {
"INVIDEO": "s3://initial-videos/video.mp4",
"INSUBTITLES": "s3://transcribed-to-review/transcribe_cfadc0531765c2f6_video.mp4.json",
"OUTBUCKET": "transcribed-to-review",
"OUTLANG": "es de",
"REGION": "eu-central-1"
},
jobRole: inContainerBatchRole,
executionRole: inContainerBatchRole,
}),
});
Testing
And this is another great thing. We can test our construct against definition results. It’s simple as:
test('Init S3 Bucket created with correct permissions', () => {
const app = new cdk.App();
// WHEN
const stack = new CdkTs.CdkTsStack(app, 'MyTestStack');
// THEN
const template = Template.fromStack(stack);
template.resourceCountIs('AWS::S3::Bucket', 4);
template.resourceCountIs('AWS::S3::BucketPolicy', 4);
template.hasResourceProperties('AWS::S3::Bucket', {
BucketEncryption: {
"ServerSideEncryptionConfiguration": [
{ "ServerSideEncryptionByDefault": { "SSEAlgorithm": "AES256" } }
],
}
});
template.hasResource('AWS::S3::Bucket', {
DeletionPolicy: 'Delete',
UpdateReplacePolicy: 'Delete',
});
});
Results
You can see the results posted as videos. The first one is an original movie created via Amazon.
Summary
Ok, that will be all. The main part of the logic was written in Python, which I didn’t discuss in detail here. It was mostly based on the core code written by Rob Dachowski, with some refactoring and code updates. While Rob’s post focuses more on the ML process, my focus was on the CDK implementation.
I found the CDK implementation to be very satisfying and fast. It was my first substantial interaction with AWS CDK, and it won’t be the last. In the future, you can expect more articles from me based on TypeScript implementation. I’m eager to dive into AWS’s CI/CD solutions, implement complex networking infrastructure, or build some Step Function projects.
With that being said, thank you, and have a great day!
Code
As always you can find my code here: